In order to
program objects, a standard is required for ensuring that the objects will not interfere with each other. A modeling language can be loosely described as a "meta-language," or abstract representation of language for software designing purposes. Initially, modeling language was considered to be part of the programming technique; programming teams might follow basic guidelines so they could communicate with each other. Gradually, the various modeling languages converged into a standard that is universally taught. One of the benefits of this has been the creation of an
open-source library of
software objects and
tools that can be adapted readily to a core program.
In 1997, the
Object Management Group (OMG) released the first version of the Unified Modeling Language (UML), which probably contributed to the subsequent popularity of OOP. Initially, the paucity of open-source objects posed a problem; in order to create large numbers of mutually compatible applications based on objects, one needs an immense number of program objects for all the detailed subroutines that a full-fledged application comprises. Object-oriented programming is especially unsuited to the conventional variety of intellectual property rights, since proprietary objects can only be used by the original developer, or else, require
complex licensing agreements. The UML seems to have had its greatest impact in the rapid and impressive development of the online
content management software (CMS) since '04, most notably
Drupal.
The UML is a set of freely available standards (
download) that are roughly analogous to any number of industrial methodologies (TQM, etc.). From these standards have evolved a large number of UML development tools, most notably the UML diagrams.
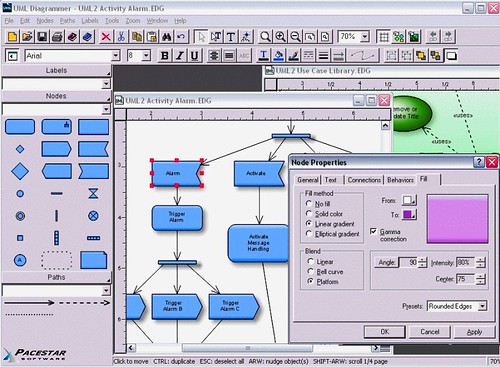
Click on image for larger viewThe illustration above is a screencapture of a program called Pacestar UML Diagrammer, whose purpose--shockingly enough--is to generate UML diagrams. There are
13 diagram types; the one shown in the active window above is a
class diagram, with a
case diagram in the background. All thirteen are listed below, with links to an excellent site explaining their purpose. As one realizes the complexity of the symbolic language that was developed for UML,one begins to understand the sweeping importance UML has had on modern (post-2004) software design. Firstly, UML 2.0 (released that year) was the industry standard for symbolic analysis of the operation, architecture, and functionality of object oriented software; secondly, new software applications tend to be object-oriented; and thirdly, OOP was becoming much more popular than it had been in the past precisely because UML was increasing the ease of OOP relative to softwares for which something like UML did not--or could not--exist.
__________________________________________
Object Constraint Language:OCL is a formal system of semantics which is used for establishing the correctness of a "statement" in a programming language. As the name implies, it may
constrain an object, by excluding certain types of statements.
Pollice: For example, it could help you indicate that, to be assigned a room, a specific course must have at least six students enrolled. With OCL you could annotate the association between the Course and Classroom classes to represent the constraint, as shown in Figure 1. As an alternative to the note shown in this figure, you could use a constraint connector between the Course and Classroom classes.
Pollice's article is very enthusiastic about OCL, which is often necessary for an instructor (I usually find I can learn a concept faster if I believe, or convince myself, that the concept is brilliant). He illustrates the difference between a set of semantic rules, which is what OCL is, and an actual language (which would have an
explicit syntax and vocabulary). Human languages have surprisingly universal semantics, something that is entirely untrue in either mathematics or programming languages; there, semantic rules vary depending on the logical relationships being manipulated. According to Pollice, OCL has very mathematically-oriented semantics, which makes it especially powerful since mathematics has evolved a very profound, comprehensive semantic structure, whereas programming languages tend to have very rudimentary rules of syntax that are peculiar to each one).
In contrast, many programming languages have semantic rules that are comparatively closer to formal English (e.g., COBOL); this is actually something of a waste for programming objects, an object usually performs a very specific mathematical or logical operation that has no use for the arbitrary and alien constraints of
human semantics, which are designed to describe tangible reality. OCL rules for what constitute acceptable language for objects under each objects peculiar conditions and contraints are, things that ought to be applied as understood by the programmer as a tool; the programmer ought not to try to master the entire codex of OCL rules. The benefits of expanding one's knowledge of OCL is that one can learn to think formally, thereby expanding one's power to discern appropriate design approaches.
(OGL SOURCE: Gary Pollice, "
Formally speaking: How to apply OCL")
__________________________________________
CRITICISM OF UML:Needless to say, for anything as influential as UML has been, there are criticisms; what's surprising is how mild they are. For the most part, these consist of inadequacies and omissions in the language.
Scott W. Ambler laments that
UML is a long way off from true computer-aided software engineering (CASE), and developers are still obligated to develop proprietary extensions to it in order to generate executable code or derive UML models from existing code.
Another criticism is the proliferation of diagrams; while several new ones have been added for UML 2.0, it seems that the large number reflects the sort of committee-induced compromise between incompatible design approaches: include the tools to do both.
This complaint also arises with the logic. UML authorizes the use of OCL semantics, English (detailed semantics) and its own peculiar set, there's an argument that the varied semantic structures defeat the purpose of any. It's unclear if this is necessarily a flaw, though, since different objects may require different semantic structures.
__________________________________________
NOTES:
Complex licensing agreements: frequently an application published for any particular market has many features that any one user is unlikely to use. Plug-ins may well be an option, but in cases where they are not, there is a problem of pricing licenses for proprietary software objects when the developer of the main program expects only 10% or so of users to ever use the feature.
Diagram types: these are (1)
Class, (2)
Component, (3)
Composite structure, (4)
Deployment, (5)
Object, (6)
Package, (7)
Activity, (8)
State Machine, (9)
Use case, (10)
Communication, (11)
Interaction overview (UML 2.0), (12)
Sequence, & (13)
UML Timing (UML 2.0);
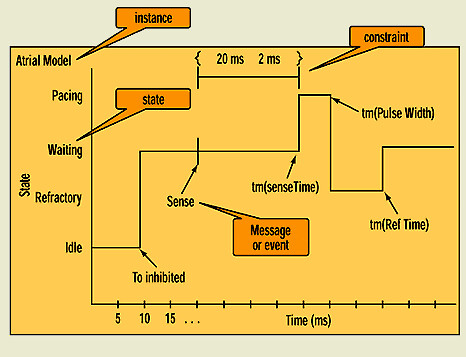
UML Timing diagram; click for source__________________________________________
ADDITIONAL READING & SOURCES: Wikipedia entries for
Object-oriented programming:
Object modeling language,
Unified Modeling Language (UML);
Executable UML;
Unified Modeling Language (UML) page; OMG; Mandar Chitnis, Pravin Tiwari, & Lakshmi Ananthamurthy, "
UML Overview"; Bruce Powel Douglass, "
UML 2.0 Incrementally Improves Scalability And Architecture"; Scott W. Ambler, "
Be Realistic About the UML: It's Simply Not Sufficient";
Labels: programming, semantics



{kind=link}